Dữ liệu lớn sẽ giúp trả lời "cái gì" chứ không phải "tại sao", và thường chỉ cần vậy là đủ.
Bạn có biết, mỗi ngày chúng ta tạo ra 2,5 nghìn tỉ tỉ tỉ (mười tám số 0) byte dữ liệu. Dữ liệu đang bùng nổ với tốc độ chóng mặt, chỉ hai năm gần đây đã tạo ra đến 90% lượng dữ liệu trên toàn thế giới. (Ước tính, nếu ghi tất cả dữ liệu hiện có trên thế giới lên đĩa CD rồi xếp chồng các đĩa lên nhau, chúng ta sẽ có năm cột CD cao đến mặt Trăng). Dữ liệu này từ đâu? Mọi nơi, ví dụ như từ những chiếc cảm biến để thu thập thông tin thời tiết, những thông tin được đưa lên các trang web mạng xã hội, những bức ảnh và video kỹ thuật số, tín hiệu GPS của điện thoại di động, giao dịch mua bán...
Tên gọi “dữ liệu lớn” dễ làm cho người ta chỉ nghĩ đến kích cỡ hay quy mô. Nhưng không chỉ vậy, dữ liệu lớn còn có đặc tính quan trọng khác đó là khả năng chuyển hóa thế giới muôn màu vốn chưa từng định lượng được trước đây thành dữ liệu, như mối quan hệ bạn bè trên mạng xã hội Facebook chẳng hạn.
Khi mẫu là tất cả
Gần như suốt chiều dài lịch sử, chúng ta chỉ làm việc với lượng dữ liệu tương đối nhỏ vì thiếu các công cụ thu thập, quản lý, lưu trữ và phân tích thông tin. Thông tin được chắt lọc để dễ kiểm tra. Đây chính là tinh thần của thống kê hiện đại, xuất hiện từ cuối thế kỷ XIX và trở thành công cụ để lý giải những vấn đề phức tạp ngay cả khi chỉ có ít dữ liệu.
Việc thu thập thông tin trước đây được thực hiện bằng cách lấy mẫu. Khi việc thu thập dữ liệu tốn kém, việc xử lý khó khăn và mất nhiều thời gian, mẫu là vị cứu tinh. Việc lấy mẫu dựa trên quan điểm cho rằng trong biên độ sai số nhất định có thể từ một nhóm nhỏ (mẫu) suy ra điều gì đó của cả tập hợp lớn, miễn là mẫu được chọn ngẫu nhiên. Ví dụ, người ta thăm dò ngẫu nhiên vài trăm người trước cuộc bầu cử để dự đoán kết quả trên cả nước.
Cách này cho kết quả tốt với các vấn đề đơn giản, nhưng không thể áp dụng khi cần phân tích sâu hơn, ví dụ như ứng cử viên nào có nhiều khả năng được phụ nữ độc thân dưới 30 tuổi bỏ phiếu bầu? Khi đó mẫu gần như vô dụng vì có thể chỉ có vài người thỏa tiêu chí, quá ít để rút ra kết luận có tính đại diện. Vấn đề được hóa giải nếu số mẫu mở rộng bao trùm tất cả (thăm dò tất cả mọi người).
Ví dụ này đặt ra một vấn đề khác của việc sử dụng một vài dữ liệu thay vì tất cả. Trước đây, khi thu thập chỉ một ít dữ liệu, người ta thường phải quyết định ngay từ đầu thu thập cái gì và dùng như thế nào. Giờ đây, khi thu thập tất cả dữ liệu, chúng ta không cần phải biết trước. Tất nhiên, không phải lúc nào cũng có thể thu thập được mọi dữ liệu, nhưng so ra việc này khả thi hơn việc “suy diễn” từ mẫu.
Tuy nhiên ở đây có sự đánh đổi. Khi tăng quy mô, chúng ta có thể sẽ phải hy sinh sự tinh gọn của dữ liệu và chấp nhận một chút “lộn xộn”. Quan điểm này đi ngược lại cách người ta làm việc với dữ liệu hàng chục năm qua. Tuy nhiên, về mặt nào đó, nỗi ám ảnh về sự chính xác là cảm xúc giả tạo do môi trường thông tin hạn chế. Khi không có nhiều dữ liệu, các nhà nghiên cứu phải cố đảm bảo những con số mà họ nhọc công thu thập được chính xác nhất có thể. Giờ đây với vô số dữ liệu chúng ta có thể chấp nhận một chút sai số (miễn là toàn bộ dữ liệu không sai lệch), bù lại có được khả năng phân tích thấu đáo.
 | Ví dụ trong dịch thuật. Có vẻ như máy tính hiển nhiên sẽ dịch tốt vì có khả năng lưu trữ nhiều thông tin và tìm kiếm nhanh chóng. Nhưng nếu chỉ tra từ điển rồi thay chữ, bản dịch sẽ rất tệ. Ngôn ngữ rất phức tạp. Google có cách tiếp cận khác, khai thác nhiều dữ liệu hơn từ Internet “lộn xộn”: thu thập bản dịch từ nhiều trang web với mọi ngôn ngữ, kể cả các bản ‘scan’ từ dự án quét sách khổng lồ của hãng. Lượng tài liệu mà Google phân tích lên đến hàng tỉ. Kết quả là bản dịch của Google khá tốt, có thể dịch đến 65 ngôn ngữ. |
Tương quan thay nhân quả
Hai thay đổi trong cách tiếp cận dữ liệu – tất cả thay vì một vài (mẫu), rộng thay vì tinh – dẫn đến sự thay đổi thứ ba: tương quan thay vì nhân quả. Thay vì cố gắng để tìm hiểu căn nguyên của sự việc, chúng ta có thể chỉ cần tìm hiểu sự tương quan giữa các hiện tượng và dùng nó để giải quyết vấn đề.
Vào tháng 2/2009, Google đã gây chấn động trong giới y tế khi công bố một nghiên cứu trên tạp chí Nature cho thấy khả năng theo dõi sự bùng phát dịch cúm chỉ bằng cách sử dụng dữ liệu tìm kiếm. Mỗi ngày Google xử lý hơn một tỉ tìm kiếm chỉ riêng ở Mỹ và tất cả đều được lưu lại. Google đã lấy 50 triệu cụm từ được tìm nhiều nhất từ năm 2003 đến 2008 và so sánh với dữ liệu dịch cúm của Trung tâm kiểm soát và phòng ngừa bệnh dịch của Mỹ (CDC) để xác định sự tương quan giữa các cụm từ tìm kiếm ở địa phương nào đó với dữ liệu của CDC về việc bùng phát dịch cúm ở địa phương đó. Thực ra CDC có theo dõi lượng bệnh nhân đến khám ở các bệnh viện và phòng khám trên cả nước, nhưng báo cáo của CDC có độ trễ một hoặc hai tuần - thời gian quá dài trong trường hợp xảy ra đại dịch. Trong khi đó hệ thống báo cáo của Google làm việc gần như tức thời (theo thời gian thực).
Xu hướng bùng phát dịch cúm ở Mỹ
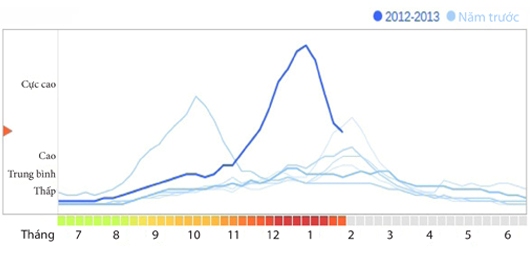
Kết quả của Google chỉ đơn giản là sự tương quan. Nó không cho biết lý do tại sao người ta thực hiện tìm kiếm thông tin về bệnh cúm. Có thể vì cảm thấy bị bệnh, nghe tiếng hắt hơi ở nhà bên, hoặc do lo lắng sau khi nghe tin dịch? Hệ thống của Google không biết điều này, nhưng nó cung cấp thông tin đủ để chính phủ biết điều gì đang diễn ra và cần phải làm gì. Đây là một ví dụ tốt về việc tìm ra sự tương quan có thể đem lại lợi ích to lớn, ngay cả khi nguyên nhân còn mơ hồ.
Tất nhiên, biết được nguyên nhân đằng sau sự việc là mong muốn chính đáng. Vấn đề là nguyên nhân thường rất khó tìm ra, và nhiều lúc khi chúng ta nghĩ rằng mình đã xác định được thì thường đó chỉ là “ảo ảnh”.
Vẫn có chỗ cho chúng ta
Dữ liệu lớn được cho là sẽ định hình lại cách chúng ta sống, làm việc và suy nghĩ. Thế giới quan lâu nay của chúng ta được xây dựng trên nền tảng mối quan hệ nhân quả đang bị thách thức bởi sự vượt trội của mối quan hệ tương quan. Nhưng dữ liệu lớn là tài nguyên và công cụ, dùng để thông báo chứ không phải giải thích, đưa tới sự hiểu biết nhưng cũng có thể dẫn đến sự nhầm lẫn, tùy thuộc vào việc chúng ta vận dụng nó như thế nào.
Với dữ liệu lớn, chúng ta có thể tiến hành các phép thử nhanh hơn và khám phá theo nhiều hướng hơn. Nhưng nhiều khi dữ liệu không thể chỉ ra những thứ chưa có. Nếu Henry Ford dùng dữ liệu lớn để tìm hiểu điều khách hàng muốn, câu trả lời có thể sẽ là "một con ngựa nhanh hơn" (câu nói nổi tiếng của ông) chứ không phải ô tô. Trong thế giới của dữ liệu lớn, vẫn có chỗ dành cho sáng tạo, trực giác, mạo hiểm và tham vọng, những đặc tính thuộc về bản năng con người. Chính những yếu tố này tạo nên sự khác biệt, đột phá để thoát khỏi những khuôn thức cũ kỹ và những lời giải máy móc.